Trends in forest carbon papers in the last 20 years
November 10, 2020
analytics science tidytext carbon forest measurementsThe number of peer-reviewed research publications on forest carbon has exploded in recent decades. From the signings of the Kyoto Protocol in 1997 to the Paris Agreement in 2015, much of the science and research conducted has been in response to the global challenges and opportunities that forests provide by sequestering and storing carbon.
Forest carbon has also been increasingly studied in forest management and silvicultural practices. New technologies and remote sensing have also brought about new ways to inventory forests for the biomass and carbon they store.
The number of peer-reviewed studies dealing with forest carbon is overwhelming, to the point that no one in their right mind would have the capacity to read every paper. This post describes how text mining can be used to investigate trends in forest carbon research over the last 20 years.
Peer-reviewed publications in forest carbon
To compile a data set, Web of Science was queried for all peer-reviewed papers containing the term “forest carbon”. Specifically, a paper was included in the data set if the term “forest carbon” was included in its abstract, title, or keyword field.
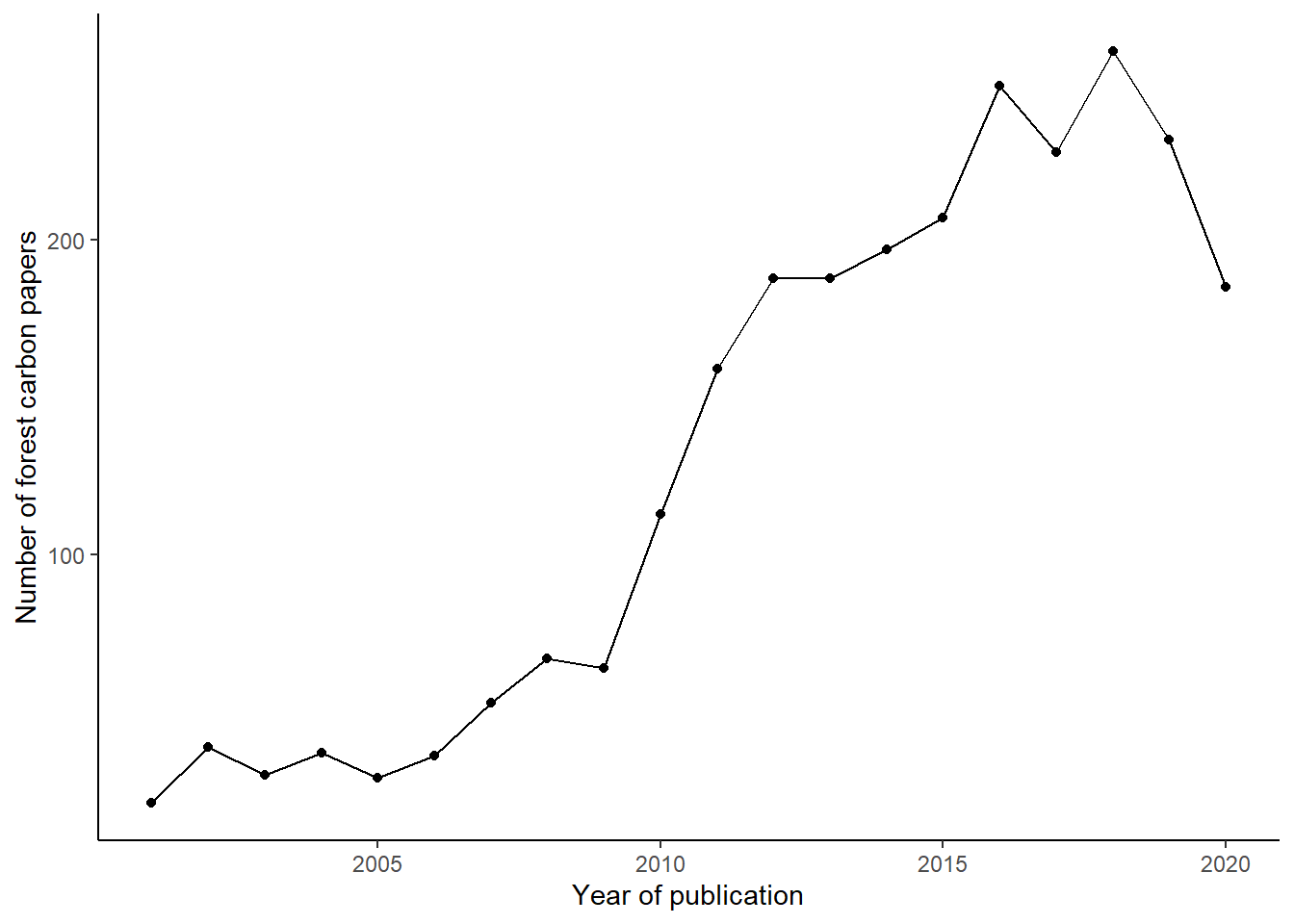
In total there were 2,668 papers obtained between 1985 and 2020. The number of forest carbon papers published since 2001 represent 97% of the data, or 2,582 papers:
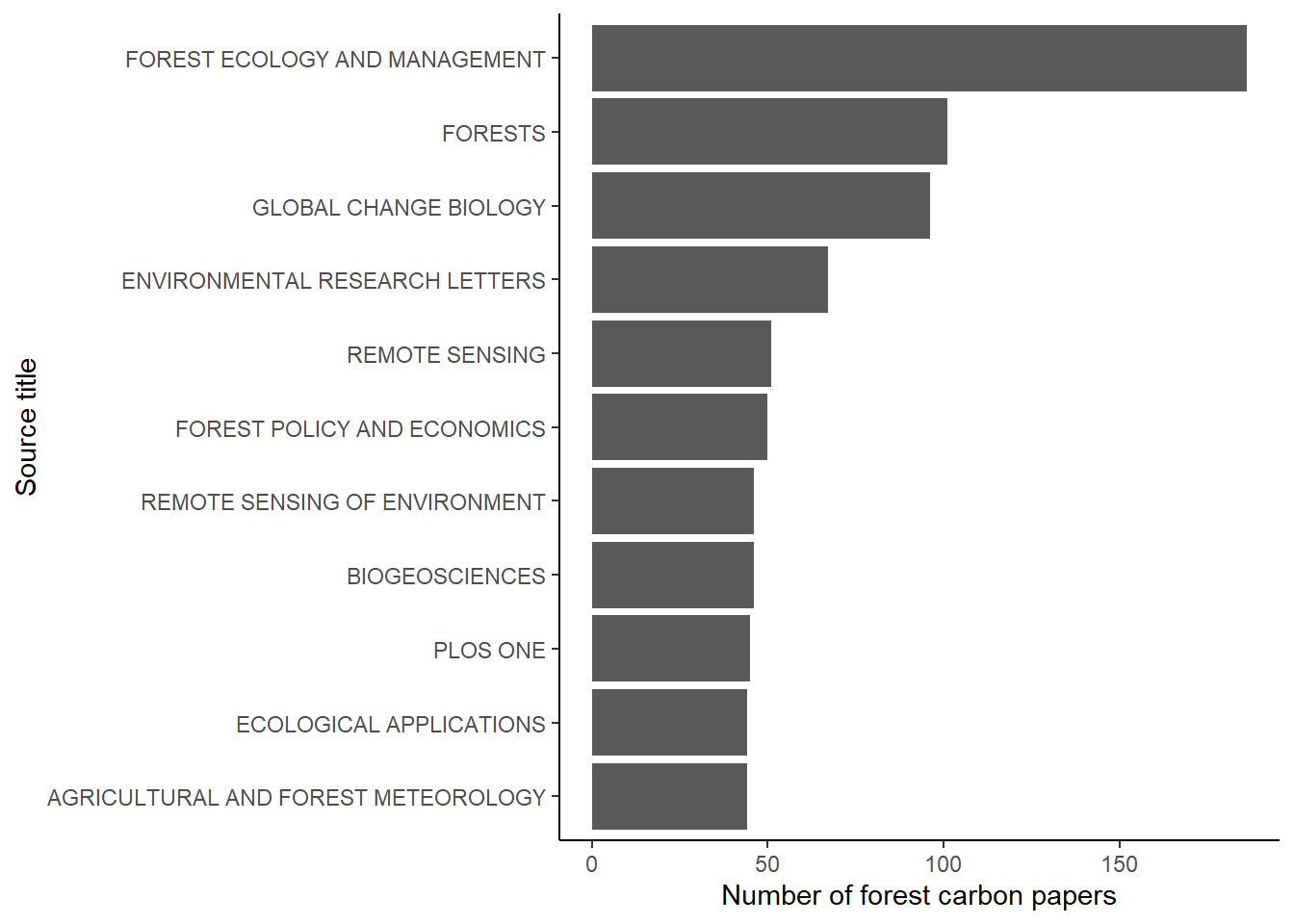
The journals Forest Ecology and Management, Forests, and Global Change Biology are the three that have published the most forest carbon paper since 2001:
Trends in forest carbon research in the last 20 years
We might be interested in seeing which topics have been covered in forest carbon papers in the last 20 years. Using the tidytext package in R along with the great examples in the Text Mining with R book, we can do just that.
The variable called term frequency-inverse document frequency (tf-idf) is a useful metric that determines important keywords in a string of text. This metric increases the weight for words that are not used very much while ignoring common words like “is”, “the” and “of”.
The figure below shows the highest tf-idf scores for all of the titles from papers that examined forest carbon for each five-year group. In other words, the figure shows the most common words used in forest carbon research studies through time:
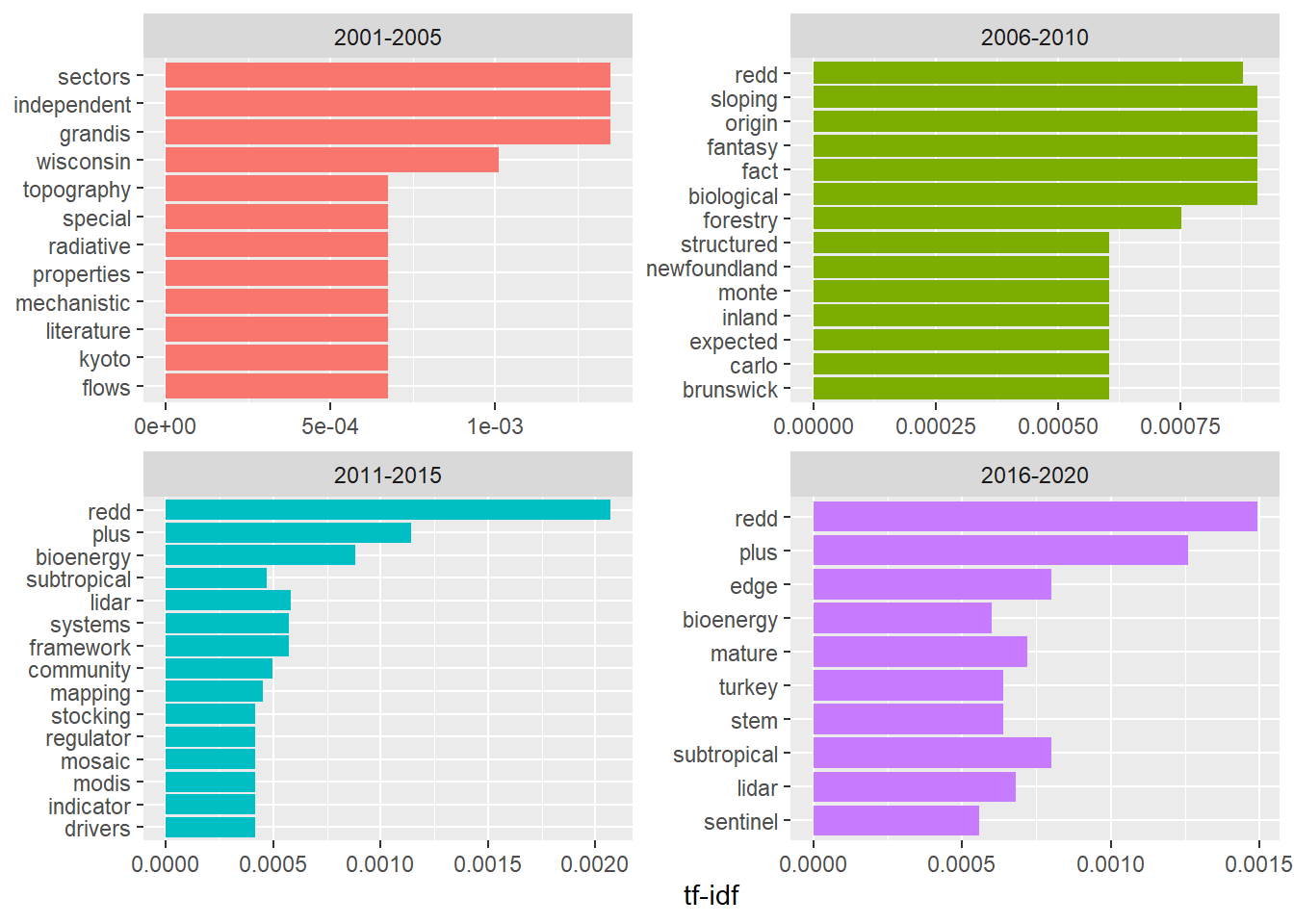
We can see different keywords arising at different time periods throughout the last 20 years, indicating different priorities in forest carbon research. In the early 2000’s, the number of publications were lower but terms such as “kyoto” refer the the recently signed Kyoto Protocol. A number of geographic names appear in the most common words (e.g., “brunswick”, “newfoundland”, “wisconsin”), likely a result of local studies on forest carbon that occurred in those regions.
Beginning in 2006, “redd” made its mark and continues to be one of the most common words in paper titles, referring to reducing emissions from deforestation and forest degradation. The word “plus” joins it beginning in 2011, a reflection of the increase in popularity of the REDD+ program.
The word “bioenergy” and “subtropical” also appear beginning in the 2011 year group. Of note in more recent years in the increase in use words relating to technology ans remote sensing. Words such as “lidar”, “mapping”, “modis”, and “sentinel” are examples of this.
Conclusion
Research on forest carbon has leaped forward in recent decades. There are 2,582 peer-reviewed papers that have been published on forest carbon topics in the last 20 years. In recent years, more terms relating to technology and remote sensing have been incorporated into titles of forest carbon papers.
–
Thanks to Samuel Neal and Cindy Zheng for the inspiration for this post based on their excellent article looking at keywords in COVID-19 papers published in last month’s issue of Significance.
By Matt Russell. Sign up for my monthly newsletter for in-depth analysis on data and analytics in the forest products industry.