Which forest biometrics researchers get the most citations?
November 30, 2019
faculty publishing Google Scholar forest measurements forest inventory citations web scraping productivityResearchers in the forest and natural resource sciences are measured by their productivity: how many publications they write and how many times those publications are cited by other researchers. Researchers that have many publications that are cited in the literature by others generally have rewarding careers and are promoted.
In 2017 I wrote a blog post for the Ecological Society of America’s Early Career Ecologist section that provided some evidence that early-career scientists publish earlier in their careers compared to more senior researchers.
When I wrote that post I used data from my own Google Scholar profile. I manually went through the data, including adding together citation counts and looking up researcher profiles to see when their PhD’s were awarded. Needless to say, it turned out to be very messy for what I thought would be a quick analysis and blog post.
I was happy to see that a package existed that can scrape data from Google Scholar and provide a number of useful metrics.
R’s scholar package
Many faculty at colleges and universities have a Google Scholar page. (For an example, see mine.) Having a Google Scholar page allows faculty to display their research publications, track the number of citations they receive for their articles, and interact with their coauthors.
The scholar package was developed by James Keirstead in R to extract citation data from Google Scholar. You can also obtain information about a specific researcher, compare multiple researchers, and predict future h-index values. (An h-index is the largest number h in which h publications have a least h citations.)
You can install and call the scholar library by using:
#install.packages("scholar")
library(scholar)The scholar package can be used by identifying the Google Scholar ID for each researcher. The Google Scholar ID can be found at the end of the URL on each profile page:
How to find the Google Scholar ID.
You can specify the Google Scholar ID for a researcher and then obtain information from their profile using the get_profile() function:
# Define the ID for Matt Russell
id <- '4OO83OcAAAAJ'
# Get Matt's profile information
get_profile(id)## $id
## [1] "4OO83OcAAAAJ"
##
## $name
## [1] "Matthew Russell"
##
## $affiliation
## [1] "University of Minnesota"
##
## $total_cites
## [1] 739
##
## $h_index
## [1] 16
##
## $i10_index
## [1] 26
##
## $fields
## [1] "verified email at umn.edu - homepage"
##
## $homepage
## [1] "http://health.forestry.umn.edu/"
##
## $coauthors
## [1] "Christopher Woodall" "Grant M. Domke" "Anthony D'Amato"
## [4] "Aaron Weiskittel" "Shawn Fraver" "Ram K. Deo"
## [7] "John W Coulston" "Charles Hobart Perry" "Laura Kenefic"
## [10] "Warren Cohen" "Hans-Erik Andersen" "Joshua Puhlick"
## [13] "Harold Burkhart" "Michael J. Falkowski" "John A. Kershaw, Jr."
## [16] "Brian Palik" "Tuomas Aakala" "Mark Ducey"
## [19] "Ken Skog" "sassan saatchi"Then, you can obtain the number of citations by year for any researcher. To do this, you’ll use the get_citation_history() function:
# Get Matt's citation history, by year
get_citation_history(id)## year cites
## 1 2010 3
## 2 2011 3
## 3 2012 17
## 4 2013 18
## 5 2014 31
## 6 2015 62
## 7 2016 113
## 8 2017 141
## 9 2018 170
## 10 2019 164Forest biometrics faculty productivity
I was interested in looking at the citations for some authors I was familiar with. Specifically, I investigated all authors from the following textbooks in the disciplines of forest measurements, growth and yield, and stand dynamics. These textbooks are commonly used in undergraduate and graduate courses across forest and natural resource departments:
- Forest Measurements, Sixth Ed. by Burkhart et al.
- Forest Growth and Yield Modeling by Weiskittel et al.
- Forest Dynamics, Growth and Yield by Pretzsch
- Modeling Forest Trees and Stands by Burkhart and Tome
- Forest Mensuration, Fifth Ed. by Kershaw et al.
- Forest Stand Dynamics by Oliver and Larson
- Forest Management: To Sustain Ecological, Economic, and Social Values by Davis et al.
Including all coauthors on these books amounts to 18 unique researchers. After searching for each author, 10 of them maintain a Google Scholar profile. The following data set includes their name, Google Scholar ID, number of citations throughout their career, and the number years in their career.
## # A tibble: 10 x 4
## # Groups: name [10]
## name id num_citations career_years
## <fct> <fct> <int> <int>
## 1 Hans Pretzsch _HQsysQAAAAJ 13863 21
## 2 Harold Burkhart mqzZk3gAAAAJ 10945 39
## 3 Jerome Vanclay N1MKi-oAAAAJ 10536 28
## 4 Bruce Larson ookqs8gAAAAJ 10102 33
## 5 Chadwick Dearing Oliver MkQKfx0AAAAJ 9285 34
## 6 Margarida Tome GR9rjA4AAAAJ 5540 23
## 7 Pete Bettinger rvCOS60AAAAJ 5430 30
## 8 John A. Kershaw, Jr. Ah6KRK4AAAAJ 4235 39
## 9 Mark Ducey 5JseyAcAAAAJ 3290 19
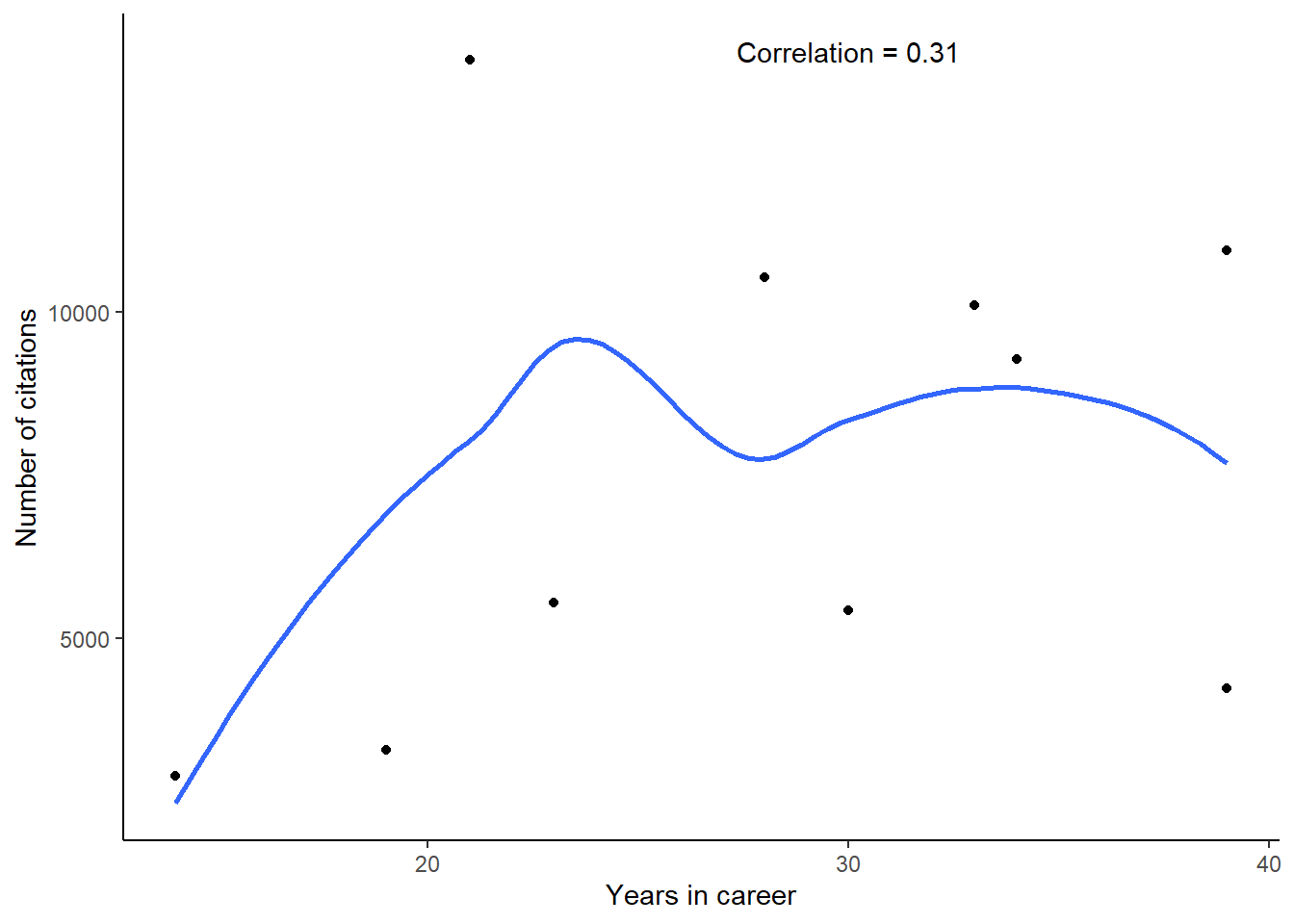
## 10 Aaron Weiskittel e7z1aLEAAAAJ 2891 14For these authors, the correlation between the length of their career and total number of citations is 0.31:
Visualizing biometrics faculty productivity
We can extract all of the Google Scholar IDs for the ten researchers by using a concatenate function c().Then we can obtain a data frame comparing the number of citations of each researcher to their work in a specific year. This is accomplished with the compare_scholars() function.
Finally, we can compare career trajectories by using the compare_scholar_careers() function:
# Define the IDs for all researchers
ids <- c('e7z1aLEAAAAJ','mqzZk3gAAAAJ','Ah6KRK4AAAAJ','N1MKi-oAAAAJ',
'_HQsysQAAAAJ','GR9rjA4AAAAJ','5JseyAcAAAAJ','MkQKfx0AAAAJ',
'ookqs8gAAAAJ','rvCOS60AAAAJ')
# Compare number of citations in a specific year
compare_scholars(ids)
# Compare researchers career trajectories, based on year of first citation
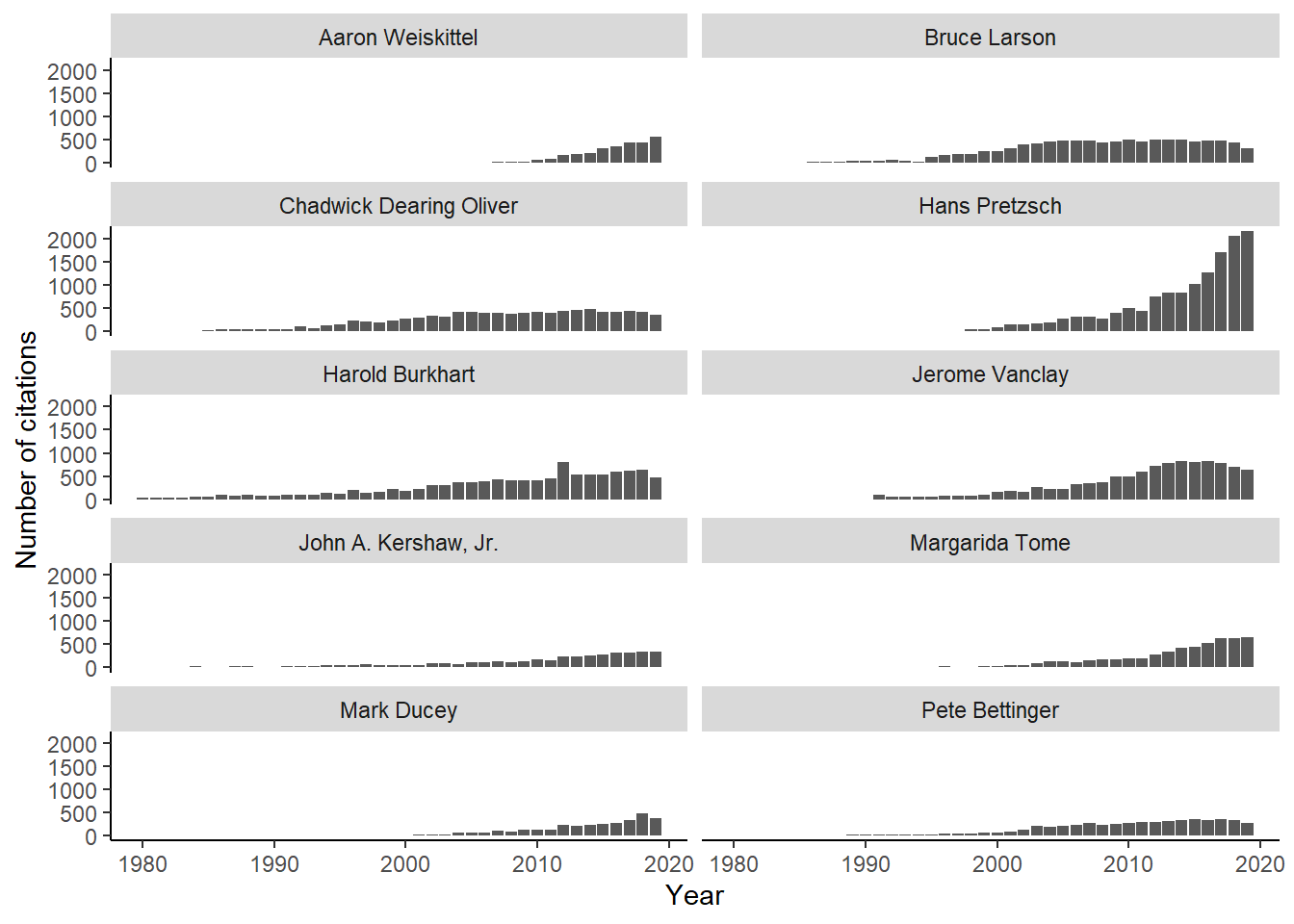
citations<-compare_scholar_careers(ids)We can compare researcher citation counts across a number of years. Notably, early- and mid-career faculty have a shorter number of years compared to more senior researchers. This is also generally reflected in the total number of citations:
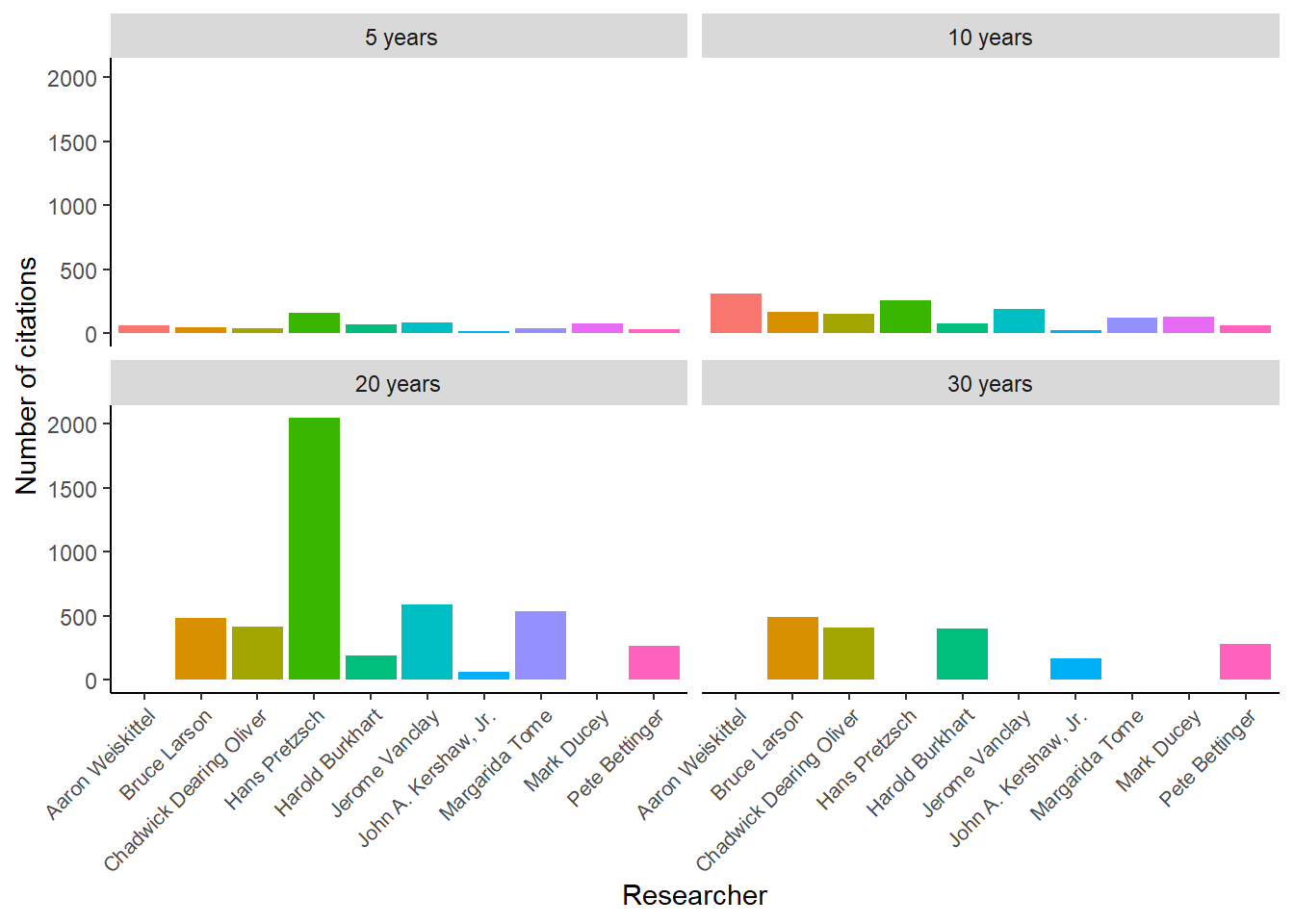
We can also “standardize” the number of citations for each researcher because Google Scholar provides these values for each researcher. The following graph shows the number of citations at years 5, 10, 20, and 30. Note that some early- and mid-career researchers have not been in their careers for more than 20 years, so no data exist for them at those time points:
Predicting future faculty productivity
Another function in the scholar package is predict_h_index(), a function that allows you to predict a researcher’s h-index up to ten years ahead into the future. The algorithm is based in part on an article published in Nature in 2012:
# Predict Matt's future h-index
ids <- '4OO83OcAAAAJ'
predict_h_index(ids)## years_ahead h_index
## 1 0 16.00000
## 2 1 19.74206
## 3 2 22.98970
## 4 3 26.01435
## 5 4 28.72624
## 6 5 31.39877
## 7 6 34.43822
## 8 7 37.27784
## 9 8 40.61042
## 10 9 44.45729
## 11 10 47.64782We can graph the future h-index values for our forest biometrics researchers for ten years ahead into the future. The predict_h_index() function shows the change in h-index values through 2029:
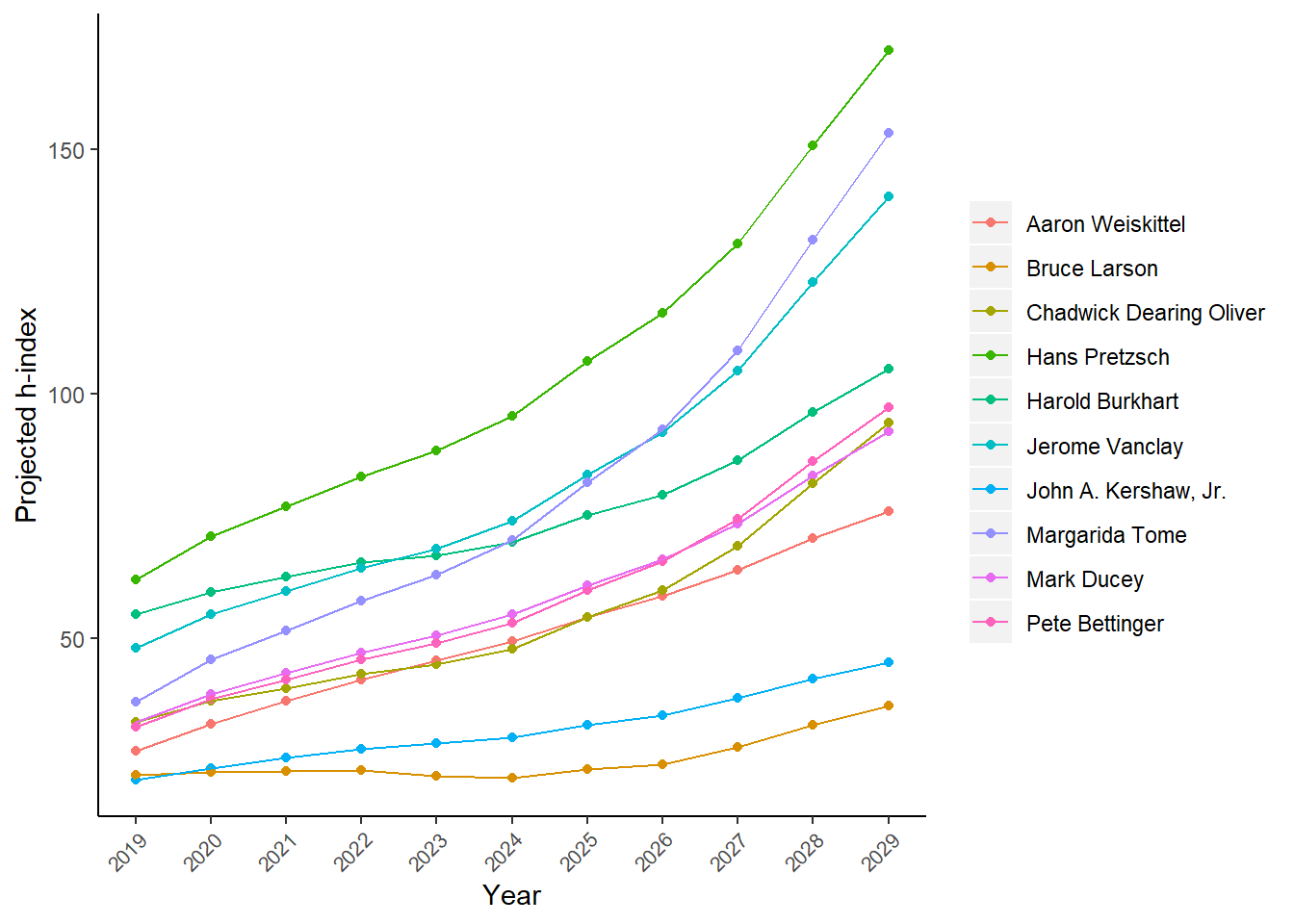
I’m not sure that forest scientists will commonly receive h-index values greater than 100 throughout their careers. So I have some reservations about its application in the forest sciences. It is interesting to note the non-linear increase in the projected h-index values.
Limitations of Google Scholar and scholar package
There are a few limitations of using an approach like this, and in using the scholar package. Most notably:
- Not everyone has a Google Scholar page. If you list all coauthors for the seven books mentioned above, 44% of authors do not have a Google Scholar page. I know that at least two of them are deceased…
- Predicting future faculty productivity is based on neuroscience. The h-index forecasts published in Nature were developed for the field of neuroscience. With the rising use and ease of access to citation data from sites like Google Scholar, similar research productivity forecasting tools could be developed that are tailored to the forest science community.
- There are many more authors in forest biometrics. This was just a sample of a few researchers, and many more could be used for a similar analysis.
Conclusion
Forest scientists and researchers (and the supervisors and department heads that evaluate them for promotion) commonly use Google Scholar to measure their research productivity. The scholar package in R is an excellent tool for assessing an individual’s research productivity and comparing research output to others. Metrics can be queried from Google Scholar and appropriate visualizations produced to aid in interpreting citation data.
By Matt Russell. Leave a comment below or email Matt with any questions or comments.